"Anonymität im Internet?"
Belegarbeit von Sebastian Lüth, Matthias Hänel und Thiemo Kreuz, Seminargruppe II99, im Mai 2002.
Anonymität im Internet
In Computernetzen wie dem Internet werden von allen Nutzern - oft unbewusst - Datenspuren hinterlassen, die nach Informationen über Interessen und Nutzungsprofile der Teilnehmer ausgewertet werden können. Aus Datenschutzgründen wäre eine Zugangsmöglichkeit zu Internet-Diensten, die mit möglichst wenigen oder sogar überhaupt keinen personenbezogenen Daten auskommt, zu bevorzugen.
Beim Surfen hinterlässt der Internetnutzer jedoch Datenspuren, die jederzeit personenbezogen die Rekonstruktion des Bewegungs- oder kurz Surfverhaltens ermöglichen. Diese Informationen fallen beispielsweise beim Provider oder mithörenden Dritten an. Neben der Möglichkeit, mit Hilfe von Verschlüsselung die Inhalte zu schützen, sollte man durch die Nutzung einer wirksamen Anonymisierung schon die Entstehung von Verbindungsdaten im Sinne des Gebotes der Datensparsamkeit vermeiden.
Anonymität im Internet heißt, für alle anderen als die Kommunikationspartner oder Dritte, denen man sich offenbart hat, nicht identifizierbar zu sein. Anfragen an Daten bereit stellende Server bleiben damit verborgen und ermöglichen beispielsweise psychologische Beratungsleistungen oder alle auf ein wirksames Identitätsmanagement basierenden Kommunikationsbeziehungen zwischen Kunden und Anbietern via Internet.
Warum anonym?
Natürlich hat nicht gleich jeder Surfer etwas Illegales im Internet vor, dennoch gibt es gute Gründe, seine Anonymität wahren zu wollen. Die Industrie, insbesondere große Firmen wie Microsoft, Netscape oder Real, wird inzwischen fast wöchentlich dabei ertappt, dass sie heimlich Informationen über ihre Kunden sammelt. Darüber hinaus gibt es unzählige Werbefirmen, die mit Hilfe von Tricks dazu in der Lage sind, das Surfverhalten detailliert mitzuverfolgen, ohne dass der Anwender etwas davon bemerkt.
Ebenso gibt es unzählige Foren im Internet, in denen man seine Meinung äußern kann. Dummerweise aber haben die Server, auf denen das Geschriebene gespeichert wird, ein längeres Gedächtnis als das richtige Leben. Mal ehrlich: Wer möchte schon mit manchen seiner Äußerungen konfrontiert werden, die schon über zehn Jahre zurückliegen, im Affekt gemacht wurden oder ganz einfach deshalb überholt sind, weil man die Meinung inzwischen geändert hat? Man muss nicht gerade in die Zwickmühlen der Justiz geraten, um die Nachteile solcher auf lange Zeit gespeicherten Aussagen zu erkennen.
Manche Unternehmen gehen sogar bereits dazu über, bei Stellenausschreibungen ein Online-Profil der Bewerber erstellen zu lassen. Einfacher ausgedrückt: Die Firmen recherchieren mit Suchmaschinen nach Spuren eines Bewerbers im Internet. Ein paar unbedachte Äußerungen in einem Gästebuch oder Forum könnten dann durchaus entscheidend für den Arbeitsplatz werden. Es ist interessant, mit einer Suchmaschine nach dem eigenen Namen zu fahnden und die dabei gefundenen Beiträge aus der Sicht einer Personalabteilung oder einfach einmal aus der Sicht des eigenen Nachbarn betrachten.
Es kann also durchaus vorteilhaft sein, im Internet seine persönlichen Ansichten nicht unter seinem eigenen Namen publik zu machen, sondern diese entweder möglichst anonym zu verbreiten oder, insbesondere beim Mailverkehr, in angemessener Form zu verschlüsseln. Das ist auch deshalb wichtig, weil es seit langem staatliche Behörden und Geheimdienste gibt, die den öffentlichen Mailverkehr an Knotenpunkten gezielt überwachen und auf verwertbare Inhalte untersuchen.
Zu guter Letzt gibt es im Internet natürlich auch sogenannte "Hacker", die mit dem Ziel unterwegs sind, persönliche Daten zu sammeln oder sogar diese unbrauchbar zu machen.
Recht auf Anonymität
Die Existenz eines Rechtes auf Anonymität im Internet ist derzeit zwischen den Experten umstritten. So leiten etwa die Datenschutzbeauftragten der Länder und der Bundesbeauftragte für den Datenschutz die Existenz eines solchen Rechts aus dem im Artikel 10 des Grundgesetzes festgeschriebenen Post- und Fernmeldegeheimnis und weiteren gesetzlichen Vorgaben der Datensparsamkeit in verschiedenen Datenschutzgesetzen ab. Von einigen Verfassungsrechtlern wird gar ein Grundrecht auf Anonymität aus dem Grundgesetz interpretiert. Allerdings mehren sich in letzter Zeit die Stimmen derer, die sich gegen ein solches Recht aussprechen. Im Zuge der Diskussionen um Kinderpornographie und Rechtsradikalismus im Internet wird gar ein Verbot der Anonymität im Internet gefordert.
Anonymisierer
Ein Anonymisierer ist ein Programm bzw. eine ganze Kommunikationsarchitektur, die Kommunikationsbeziehungen zwischen Sendern und Empfängern im Internet verschleiert, so dass Sender und/oder Empfänger der Nachricht anonym bleiben und mithörende Dritte die abgefangenen Inhalte nicht mehr den Sendern und Empfängern zuordnen können.
Die einfachsten Anonymisierer sind so genannte Proxy-Server, die eine Internetanfrage stellvertretend für den Nutzer an den Server weiterleiten. Bei dieser Grundform von Anonymisierung ist die Kommunikation aber sowohl gegenüber dem Provider als auch gegenüber dem Betreiber des Proxy selbst nicht mehr anonym. Besser geeignet sind echte Anonymisierungs-Architekturen, wie z.B. ein Mix-Netz, das durch die verschlüsselte Weiterleitung von Nachrichten zwischen den Mix-Stationen eine Reidentifizierung der Kommunikation nur noch sehr schwer möglich macht.
Mit dem am Ende dieses Beleges beispielhaft vorgestelltem "JAP" existiert ein solcher, auf einem MIX-Netz basierender, aktueller Anonymisierer.
Das IP-Protokoll

IP ist ein verbindungsloses Protokoll und als solches nicht darauf angewiesen, eine Verbindung zu einem Rechner zu "öffnen", sondern es genügt, das IP-Paket einfach abzusenden und darauf zu vertrauen, dass es schon ankommen wird. Über das Quittieren oder die Reihenfolge der empfangenen Pakete soll an dieser Stelle nicht gesprochen werden. Wichtig aus der Sicht der Anonymität sind neben den Mac-Adressen, die im unterhalb von IP liegenden Ethernet-Header stehen, lediglich die beiden IP-Adressen.
IP-Adressen bestehen aus einer 32 Bit langen Zahl, die allein aus Gründen der Lesbarkeit normalerweise in Form von vier durch Punkten getrennten Dezimalzahlen dargestellt werden. Zum Beispiel "193.174.8.65" oder "194.209.3.75". Bei der Entwicklung des IP-Protokolles war im Prinzip vorgesehen, jedem Gerät eine weltweit eindeutige IP-Adresse zuzuordnen. Darüber wäre wiederum jederzeit eine eindeutige Identifizierung jedes einzelnen Rechners möglich.
Im Idealfall, der heute bereits zum Ausnahmefall geworden ist, ist diese Identifizierung tatsächlich möglich. Allein über die 4 Byte umfassende IP-Adresse kann der Rechner, welcher die Anfrage durchführte, benannt und wiedererkannt werden. Die in diversen Sprachen vorhandene Funktion "gethostbyaddr()" reicht in der Regel aus, um der numerischen Adresse einen Namen zuzuordnen. Dienste wie zum Beispiel RIPE (http://www.ripe.net/) oder AMNESI (http://www.amnesi.com/) bietet eigene Datenbanken, die praktisch "rückwärts" detaillierte Informationen (einschließlich Anschrift und Telefonnummer des Besitzers etc.) zu nahezu jeder IP-Adresse liefern können.
Eine weitere Informationsquelle soll hier nur am Rande erwähnt werden. Auf der Internetseite der DENIC (http://www.denic.de/), der Registrierungsbehörde für auf ".de" endende Domainnamen, steht ein Service zur Verfügung der es erlaubt, jeder beliebigen de-Domain einen Besitzer (wiederum incl. Anschrift etc.) zuzuordnen. Damit wird - natürlich rechtlich fundiert - die Handhabe mit eigenen Domainnamen ebenso wenig anonym wie die direkte Preisgabe der Anschrift.
Dynamische Vergabe von IP Adressen
Der rund vier Milliarden umfassende reservierte IP-Adressraum reicht schon längst nicht mehr aus, um alle Endgeräte anzusteuern.
Bei der dynamische Vergabe von IP-Adressen wird eine geringe Anzahl von Adressen einer großen Anzahl von Rechnern je nach Bedarf zugewiesen. Dieses Verfahren wird vor allem bei der Einwahlprozedur der großen Provider angewendet, es ist aber auch für lokale Netz geeignet. Der Benutzer bekommt für die Dauer einer Verbindung eine IP-Adresse zugeteilt. Das bekannteste Verfahren dafür ist DHCP (Dynamic Host Configuration Protocol).
Für unseren Aspekt der Anonymität ergibt sich daraus die schwerwiegende Konsequenz, dass eine ein-eindeutige Zuordnung nicht mehr ohne weiteres möglich ist. Im Normalfall - also so lange keine Straftat und eine ausreichende rechtliche Handhabe vorliegt - kann von Seiten des Servers lediglich ermittelt werden, über welchen Anbieter der Anwender sich im Netz bewegt bzw. welchem Intranet er angehört. Natürlich ist es dank der gesetzlich inzwischen vorgeschriebenen Logfiles möglich, eine Zuordnung zu treffen. Dies kann wie gesagt aber nur mit ausreichender Begründung stattfinden.
Network Address Translation
Die "Network Address Translation" (NAT) erlaubt es, über ein Gateway im Internet eine andere IP-Adresse zu verwendet als im lokalen Netz. Es ist sogar denkbar, ein komplettes privates Netz mit einer einzigen externen IP-Adresse zu betreiben. Im Gegensatz zur dynamischen Vergabe, bei der die Adresse für den Zeitraum der Verbindung konstant blieb, bewegen sich hier mehrere Benutzer unter der gleichen Adresse im Netz. Dynamisch vergeben wird dabei maximal die Portnummer (dazu gleich beim TCP-Protokoll mehr). Dieses Verfahren erschwert die Verfolgung zusätzlich, ist aber prinzipiell mit den oben beschriebenen Methoden immer noch nachvollziehbar.
Das TCP-Protokoll

Die jetzt für uns einzigen relevanten Felder im Header des TCP-Protokolles sind die beiden Port-Adressen. Eine http-Anfrage beispielsweise findet im Normalfall über den Port Nummer 80 statt. Für die Identifikation und Verfolgung des Benutzers ist der Port in der Regel irrelevant. Lediglich bei einem "NAT", das wie weiter oben beschrieben mit Port-Mapping arbeitet, kann die Zuordnung einer IP/Port-Kombination zu einem Endgerät weiter verfeinert werden.
Ziele, Risiken und Nebenwirkungen von Datenerhebungen
Findige Köpfe aus dem Bereich des Marketing sind auf die Idee gekommen, dass ein Unternehmen Kosten sparen könne, wenn man Werbung lediglich der Zielgruppe zukommen lässt oder Web-Seiten dynamisch gestaltet, so dass sie auf die Interessen, Bedürfnisse und Wüsche des Surfers abgestimmt sind. Um dies realisieren zu können, muss man allerdings die Interessen, Bedürfnisse und Wünsche des Gegenüber kennen. Wie erfährt man so etwas einfacher, als wenn man zum Beispiel das Internet-Nutzungs-Verhalten des Surfers untersucht?
Dementsprechend haben andere Leute beschlossen, Persönlichkeitsprofile ihrer Mitmenschen zu erheben - bislang eher Lieblingsbeschäftigung von Geheimdiensten und Strafverfolgungsbehörden - diese in Datenbanken zu archivieren und sie gegen ein entsprechendes Entgelt an Interessenten zu veräußern. Deutschlands größter Datensammler bei Stuttgart hatte Mitte 1999 beispielsweise 1 Milliarde Informationen über immerhin 60 Millionen Bundesbürger vorrätig.
Die Wenigsten werden sich darüber ärgern, zielgerichtet beworben zu werden. Allerdings gehören zu den Interessenten solcher Persönlichkeitsprofile nicht nur Marketingabteilungen kostenbewusster Unternehmen, sondern auch Personalabteilungen - unter anderem im Zusammenhang mit Einstellungen (bisher in erster Linie von Führungskräften in amerikanischen Unternehmen) - Strafverfolgungsbehörden, nach wie vor Geheimdienste und das organisierte Verbrechen.
Dem FBI wurde aus Datenschutzgründen verboten, eine eigene derartige Datenbank anzulegen. Es ist jedoch erlaubt, dass sich diese Behörde im Zweifelsfall bei einer kommerziellen Datenbank mit den gewünschten Informationen eindeckt.
Zu Bedenken ist auf jeden Fall, dass die einmal gesammelten Daten über einen ziemlich langen Zeitraum verfügbar sind, ohne dass der Betroffene selbst Einfluss darauf hat. Gesetze und Wertvorstellungen in der Gesellschaft, in der man lebt, unterliegen aber einem ständigen Wandel und unterscheiden sich in anderen Gesellschaften und Ländern gelegentlich grundlegend von denen des eigenen Sozialwesens.
Um die Problematik drastisch auszudrücken: Judensterne wurden im dritten Reich jedenfalls nicht dazu benutzt, damit der Kaufmann wusste, dass ein Stern-Träger lediglich koschere Ware abnimmt.
In diesem Zusammenhang sei daran erinnert, dass Staaten, die das Attribut "demokratisch" für sich in Anspruch nehmen in den meisten Fällen so etwas wie Gewaltenteilung eingeführt haben, weil man doch irgendwann festgestellt hat, dass es den guten und fehlerfreien Menschen in der Realität nicht gibt und konzentrierte Macht- und Wissenszentren schädlich für eigentlich tolerierte Arten von Freiheit und gesellschaftliche Weiterentwicklung sind. Gleichzeitig hat man sich dann meistens auch noch für Datenschutz-Regelungen entschieden, die aber im Ernstfall - wenn die Daten erst einmal erhoben sind - nur im juristischen Zusammenhang von Bedeutung sind und den gesellschaftlichen und/oder wirtschaftlichen Schaden des Betroffenen im Zweifelsfall nicht mehr beheben können.
Wenn die negativen Nebenwirkungen bisher noch nicht in auffälligem Umfang bemerkbar geworden sind, liegt das zu einem großen Teil daran, dass große Firmen zwar inzwischen vielfach gemerkt haben, wie sie diese Daten sammeln können, aber bei der Auswertung Schiffbruch erleiden.
Web-Technologien
Webseiten- und Browsererweiterungen
Der Funktionsumfang und die Darstellungsmöglichkeiten der Web-Seiten-Sprache HTML sind vergleichsweise eingeschränkt und entwicklungsbedingt eher auf die statische Darstellung von Text und Bild ausgerichtet. Um diese Funktionseinschränkungen zu reduzieren und dynamische Elemente wie Audio- und Videoübertragungen oder Datenbankabfragen über das Netz realisieren zu können, wurden Sprachen und Technologien entwickelt, die den Web-Seiten und Browsern entsprechende Präsentationen ermöglichen.
Einige dieser Erweiterungen können auch auf Daten des Surfers oder seines Computers zugreifen oder Programme auf dessen Rechner ausführen. Von besonderem Interesse sind hierbei unter anderem die folgenden.
Plugins
... sind Programme, die dem Browser die Darstellung von Dateiformaten erlauben, die er selber nicht darstellen kann. Zu diesen Datentypen gehören zum Beispiel Audio- und Videoformat oder PDF-Dateien. Entsprechende Plugins sind der Acrobat Reader von Adobe und der RealPlayer von Real Networks. Ältere Versionen des RealPlayer sind als Datenstaubsauger berüchtigt, die den Computer des Surfers auf interessante und verwertbare Daten untersucht. Neueren Versionen soll dieses Verhalten nach Datenschützer-Protesten abgewöhnt worden sein.
CGI
CGI steht für Common-Gateway-Interface und ermöglicht dem Client-Computer Programme auf dem Server-Computer auszuführen. Diese Technologie kommt vorwiegend dann zum Einsatz, wenn über das Internet auf Datenbanken zugegriffen werden soll, also individuelle Web-Seiten erst beim Aufruf erstellt werden oder wenn Formulare zum Beispiel bei Produkt-Registrationen oder im e-commerce verarbeitet werden müssen.
Java
... ist eine plattformunabhängige objektorientierte Programmiersprache. Über das Internet können als Java-Applets bekannte Programme transferiert werden, die dann im Gegensatz zu CGI-Programmen automatisch auf dem Client-Computer ausgeführt werden und deshalb auch als Sicherheitsrisiko gelten.
ActiveX
ActiveX-Controls können im Gegensatz zu Java-Applets bisher nur im Zusammenhang mit Microsoft Windows eingesetzt werden. Ausgeführt werden sie ebenfalls auf dem Client-Computer. Als Sicherheitsrisiko gelten sie, seit bekannt wurde, dass mit ActiveX die Kontrolle über den Computer des Surfers von außen übernommen werden kann.
JavaScript
... ist eine ursprünglich von Netscape entwickelte plattformunabhängige Script-Sprache, um Unzulänglichkeiten der Webseiten-Sprache HTML auszubügeln. Die von Microsoft herausgegebene Variante heißt JScript. Beide basieren auf dem Standard ECMAScript, unterscheiden sich jedoch in einigen Funktionen. So können mathematischen Operationen vorgenommen werden, aber auch etliche Informationen über den Computer des Surfers an den Webseiten-Herausgeber geliefert werden. Außerdem werden über JavaScript auch gelegentlich ActiveX-Controls aufgerufen. Es gilt daher in punkto Sicherheit als kritisch.
VBScript
... ist eine JScript vergleichbare Sprache von Microsoft und wird, neben dem Einsatz in Web-Seiten, zusammen mit JScript als Nachfolger bzw. Ergänzung der seit MS-DOS bekannten Batch-Dateien verwendet.
Cookies
... sind je nach Browser Einträge in eine Datei (Netscape Navigator) oder eigene Dateien (Internet Explorer ab Version 4.0) die es einem Webseiten-Anbieter ermöglichen sollten, ob seine Seiten von der gewünschten Zielgruppe besucht werden. Beliebtes Einsatzgebiet ist auch die individuelle Konfiguration von Suchmaschinen oder der automatische Zutritt zu Passwort-geschützten Bereichen. Sie können nur von dem Rechner gelesen werden, der sie auch geschrieben hat. Sie werden im Normalfall nach einer gewissen Zeit automatisch wieder gelöscht. Allerdings werden inzwischen Cookies nicht nur von der Web-Seite an sich gesetzt sondern auch von eingebundenen Werbebannern aus. So ist es dem Werbebannerbetreiber möglich den Surfer über die entsprechenden Seiten zu verfolgen. Lässt der Surfer beim Werbebannerbetreiber noch ein Produkt registrieren oder hinterlässt er im Zuge eines Online-Geschäftes seine persönlichen Daten, sind die wichtigsten Daten für ein Persönlichkeitsprofil auch schon weitergegeben worden.
Browsereinstellungen
Den am weitesten verbreiteten Browsern von Netscape und Microsoft kann man vorgeben, wie sie sich beim Auftreten der im letzten Abschnitt aufgeführten Web-Seiten-Elemente verhalten sollen.
Beim Netscape Navigator sind diese Einstellungen im Menu Edit/Bearbeiten im Dialogfenster Preferences/Einstellungen unter Advanced/Erweitert zu suchen. Im Unterpunkt Navigator kann man die Plugins verwalten.
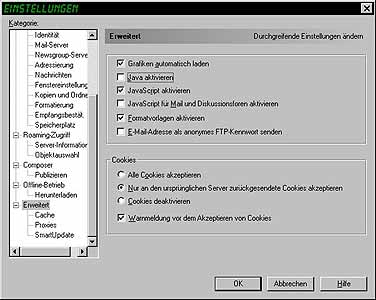
Beim Internet Explorer ab Version 4.x kann man die Konfiguration im Menu Extras, im Dialogfenster Internetoptionen, beim Register Sicherheit vornehmen. Hier wird zwischen einzelnen Netzwerkzonen unterschieden.


Seit Version 5.x verbirgt sich hier im Punkt "Dauerhaftigkeit der Benutzerdaten" als Standardeinstellung die Option "Aktivieren", die die "Kennwort speichern"-Option im DFÜ-Netzwerk aushebelt.
Was geht raus?
Privacy.net (http://www.privacy.net/) gibt darüber Auskunft was der Herausgeber einer Web-Seite oder sonstige Interessierte bei den aktuellen Browser- und Netzwerk-Einstellungen über den Surfer und seinen Computer erfahren kann und wie zum Beispiel Cookies wirken.
Privacy.net bietet auch ein äußerst hilfreiches Analyse-Werkzeug (http://privacy.net/analyze/), das alle nur denkbaren Informationen vom Client sammelt und zur Kontrolle anzeigt.
ECHELON
ECHELON oder auch Projekt 415 genannt ist ein streng geheimes Überwachungsnetzwerk. Es kann innerhalb eines Jahres Billionen von Verbindungen anzapfen. ECHELON kann spionieren bei wem es will und wann es will.
Entworfen und koordiniert von der NSA, wird das ECHELON Netzwerk dazu benutzt, gewöhnliche E-Mails, Faxe, Telexe und Telefongespräche, die über das globale Telekommunikationsnetz geführt werden, abzuhören. Im Gegensatz zu vielen anderen elektronischen Abhörsystemen, die während des Kalten Krieges entwickelt wurden, ist ECHELON in erster Linie für nicht-militärische Ziele entwickelt worden: für Regierungen, Organisationen, die Wirtschaft und für Einzelpersonen in praktisch jedem Land. Es kann weltweit jeden berühren, der mit dem Ausland (und manchmal sogar innerhalb des eigenen Landes) kommuniziert.
Das ECHELON System ist nicht dazu entwickelt worden, einen bestimmten E-Mail- oder Fax-Zugang abzuhorchen. Es ist vielmehr so, dass das System große Mengen an Unterhaltungen mit Computern abhört, um interessante Nachrichten von den Massen an uninteressanten Informationen herauszufiltern. Zu diesem Zweck ist in der ganzen Welt eine Kette von geheimen Abhörmöglichkeiten errichtet worden, um alle Hauptkomponenten der internationalen Telekommunikations-Netzwerke anzuzapfen. Dazu gehören diverse Abhörsatelliten für Kommunikation, einige landbasierte Kommunikations-Netzwerke und andere Funkkommunikationsarten.
ECHELON verknüpft all diese Möglichkeiten und versorgt die USA und ihre Verbündeten mit der Fähigkeit, eine große Menge der Kommunikation auf dieser Welt abzuhören. Die Computer an jeder Station im ECHELON Netzwerk durchsuchen die Millionen von abgehörten Mitteilungen automatisch nach Schlüsselworten, unter denen sich z.B. relevante Namen, Plätze, Adressen, Telefonnummern und andere Suchkriterien befinden. Das alles geschieht in "Echtzeit", bis der Computer die "Nachrichtendienst-Haarnadeln im Telekommunikations-Heuhaufen" gefunden hat. Details wie Zeit und Ort des Abhörens sowie die vermutete thematische Zuordnung werden automatisch gesichert, um späteren Analysen eine ausreichende Datenbasis zu stellen.
Die Computer in den Stationen rund um den Globus sind als die "ECHELON Wörterbücher" bekannt. Computer, die automatisch den Datenverkehr nach Schlüsselwörtern durchsuchen, existieren seit den 70er Jahren, aber das ECHELON System wurde von der NSA entwickelt, um all diese Computer miteinander zu verbinden und den Stationen zu erlauben, als Teil eines Ganzen zu funktionieren. Dafür existiert ein stark verschlüsseltes, mit dem Internet vergleichbares Kommunikations-Netzwerk, über das ECHELONs Wörterbuchcomputer miteinander verbunden sind.
ETSI
Es wurde der Entwurf einer Gesetzesvorlage entwickelt, der international Polizeibehörden und Geheimdiensten den Zugriff und die Überwachung im Internet gestattet. Dazu werden Methoden entwickelt, die Zugriffs- und Aktivitäten zur Überwachungen vereinheitlichen sollen.
Der Masterplan der Geheimdienste, die ihre Tätigkeiten gerne mit dem Begriff "lawful" schmücken, sieht vor, Schnittstellen zur Überwachung sämtlicher digitaler Netze wie ISDN, das Internet bis hin zu UTMS zu entwickeln. Zu diesem Zweck wird ein Meta-Standard mit dem Namen ETSI ES 201 671 entworfen, der dynamisch entlang des technologischen Fortschritts fortgeschrieben wird. Bereits jetzt ist abzusehen, dass neben Polizeibehörden zukünftig auch Staatssicherheitsdienste diesen Standard nutzen werden.
Das Szenario sieht vor, alle Vermittlungszentralen für digitale Daten mit so genannten "Handover Interfaces" auszustatten, die dem ETSI-Standard folgen. Diesem Standard liegt ein an TCP/IP angelehntes Protokoll zu Grunde. Auch wenn offiziell verkündet wird, die Abhörmaßnahmen strikt vom "normalen" Netzverkehr zu trennen, drängt sich der Verdacht auf, dass diese Technik sich auch für den Zugriff auf die Logfiles der Netzbetreiber eignen könnte. Die großen, nicht kommerziellen Security-Projekte im Internet sehen darin eine große Gefahr und fürchten, der Schritt zum "gläsernen User" wäre damit getan.
Zwischenbemerkungen
Es soll noch einmal betont werden: Anonymität im Internet ist nicht, wie von vielen Hilfsprogramm-Herstellern immer wieder behauptet, ein rein technisches Thema, das sich durch den Einsatz der richtigen Filterkombination erledigen ließe. Mit Hilfe von Filterprogrammen lassen sich Techniken zur automatischen Überwachung und Verfolgung von Benutzern mehr oder weniger gut blockieren und stören. Aber kein Programm kann verhindern, dass Benutzer sich selbst zu Opfern machen, indem sie Daten preisgeben, ihr System durch Viren und Trojaner infizieren lassen, "kostenlose" Software installieren die im Hintergrund Daten verschickt, oder einfach nur bekanntermaßen unsichere Programme benutzen, nur weil deren Hersteller so bekannt ist.
Das Internet entwickelt sich zunehmend zu einem rechtsfreien Raum für Abhörmaßnahmen. Unlängst geben Internetdienstleister den Behörden unbegrenzten Zugriff auf all ihre Kundendaten ohne vorherigen, richterlichen Beschluss, künftig sollen Internetdaten wie E-Mails, Chatbeiträge oder Logdateien vom Surfverhalten über einen Zeitraum von 7 Jahren gespeichert werden (http://www.telepolis.de/deutsch/special/enfo/7709/1.html).
Bisherige Dienste, ob Web-basiert oder über ein auf dem Anwenderrechner installiertes Programm, haben einige gravierende Mängel. Beispielsweise könnte ein Dienst wie http://www.anonymizer.com/ sämtliche Daten seiner Benutzer nach bestimmten Begriffen scannen und gegebenenfalls anhand der Verbindungsdaten (IP-Adresse) in Zusammenarbeit mit einer staatlichen Behörde die betreffende Person ausfindig machen. Häufig bieten die Dienste auch keine Verschlüsselung zwischen dem Anwender und dem entfernten Server. Den Nachteilen der deutlich längeren Ladezeit und den nervenden Werbebannern steht damit nur ein sehr geringer Gewinn an Anonymität entgegen, weshalb kaum ein Anwender solche Dienste häufig nutzt. Kostenpflichtige Dienste bieten zwar oft Verschlüsselung, ein höheres Tempo und sind frei von Werbung, die Betreiber sind damit aber auch in Besitz der Bankverbindung, des Namen und der Adresse ihres Kunden. Von Anonymität keine Spur.
Ausspionieren der Nutzer
Derzeit hat sich noch keine Technik durchgesetzt die es ermöglichen würde, jeden Benutzer sicher zu identifizieren und damit bequem über einen größeren Zeitraum zu verfolgen. Intels Idee mit der Prozessor-ID war ein Reinfall, Microsofts Passport ist derzeit kaum mehr als eine Wunschvorstellung.
Was bleibt also?
Die Datensammler müssen nehmen, was sie kriegen können. Aus diesem Grund werden riesige Datenbestände aus unzähligen kleinen Informationsbruchstücken miteinander abgeglichen, um den Wünschen und der Persönlichkeit des Benutzers auf die Spur zu kommen. Was in der Presse als Rasterfahndung noch heiß diskutiert wird, ist in der Internet-Werbebranche längst Realität.
Warum ein falscher Name nicht anonym macht
Wenn ein Benutzer sich im WWW bewegt, wird oft ein Profil von ihm erstellt. Sein Name ist zu diesem Zeitpunkt völlig unwichtig, er bekommt einfach eine Nummer zugewiesen. Mit jeder Information, die über ihn bekannt wird, vervollständigt sich das namenlose Personenprofil.
Irgendwann passiert es dann: Der Benutzer, der vorher monatelang nichts über sich preisgegeben hat, meldet sich bei einem Gewinnspiel an, gibt seinen Namen und seine Adresse ein und innerhalb weniger Sekunden werden Tausende von Datenbankeinträgen, die vorher nur eine Kennnummer hatten, mit seinem Namen verknüpft.
Es muss natürlich kein Gewinnspiel sein. Es gibt unzählige Lockangebote und unseriöse Website-Betreiber, die nach Herzenslust Daten und Adressen sammeln, um diese dann an die gierig wartende Kundschaft zu verkaufen.
Die Techniken
1. Auswertung der Serverkommunikation
Es gibt drei grundlegende Techniken, über die Surfer im WWW verfolgt werden können.
Die Serverkommunikation beinhaltet die IP-Adresse und zahlreiche sogenannte HTTP-Header, die Aufschluss über den benutzten Browsertyp, das Betriebssystem, die zuvor besuchte Webseite und die beim Verlassen der Seite aufgerufene nächste Webseite geben.
2. Cookies
Cookies sind kleine Textblöcke, die der Server an den Browser sendet und später wieder zurück bekommt und benutzen kann. Cookies werden vom Browser entweder dauerhaft oder für einen festgelegten Zeitraum gespeichert. Sie können keine ausführbaren Befehle enthalten und stellen deshalb kein direktes Sicherheitsrisiko dar. Anders ausgedrückt enthalten Cookies keinerlei Informationen, die dem Server nicht vorher schon bekannt gewesen wären - abgesehen von der Besuchshäufigkeit und der zeitlichen Einordnung. Cookies dienen häufig dazu, den Benutzer zu "markieren" um ihn später wiedererkennen zu können.
Mittlerweile sind Cookies die Standardmethode zur Verfolgung von Seitenbesuchern geworden. Beim ersten Besuch bekommt der Benutzer ein Cookie mit einer eindeutigen Kennnummer aufgedrängt und bei jedem weiteren Seitenaufruf kann der Server den Besucher daran wiedererkennen.
Das eigentliche Problem ist, dass nicht nur der Server Cookies setzen kann, der die aufgerufene Webseite liefert.
Jede von einem Webserver abgerufene Datei kann mit einem Befehl zum Setzen oder Auslesen eines Cookies kombiniert werden. Da die Werbebanner und Counter-Grafiken auf den meisten Webseiten nicht vom eigenen Server, sondern direkt von den Servern der Werbefirmen eingefügt werden, haben diese Firmen die Möglichkeit, mit Hilfe von Cookies Benutzerbewegungen auf allen angeschlossenen Partner-Webseiten zu verfolgen.
Einer der größten Banneranbieter ist die Firma Doubleclick. Um diese Firma gab es vor einiger Zeit bemerkenswerten Presserummel, weil jemand das ausgesprochen hatte, was eigentlich schon längst bekannt war. Dass Doubleclick systematisch Surfer durch das ganze World Wide Web verfolgt, deren Personenprofil speichert und zu jedem nur erdenklichen Zweck nutzt, war und ist mehr als fragwürdig.
3. Schnüffelskripte
Skripte die den Browser veranlassen, Daten zu versenden, werden dort eingesetzt, wo die Informationen, die durch die beiden oben genannten Methoden ermittelt werden können, nicht ausreichend sind. Es handelt sich in der Regel um Javaskripte, die versuchen, möglichst viele Informationen vom Browser abzufragen und an den Server zu schicken. Ein Beispiel:
Das Skript ermittelt, dass der Benutzer Windows ME und Netscape 6.1 benutzt, eine Bildschirmauflösung von 1600 x 1200 Pixeln mit 32 Bit Farbtiefe hat, vorher auf 7 anderen Seiten war von denen die letzte "http://www.autsch.de/" war, und das Flash-Plugin in Version 1.23 installiert hat. Danach ruft das Skript vom Werbeserver eine 1 x 1 Pixel große Grafik mit folgendem Namen auf: "trackerpixel-winME-NN6.1-1600-32-hst7-ref'www.autsch.de'-msf1.23-.gif". Wie man sieht, ist darin alles enthalten. Der Server braucht nur noch die im Aufruf enthaltenen Daten auszuwerten. Nach diesem Prinzip arbeiten praktisch alle bekannten Counter, die über Statistikfunktionen verfügen.
Gegenwehr
1. Auswertung der Serverkommunikation
Die Daten, die über HTTP-Header übertragen werden, lassen sich mit Filtern beliebig manipulieren. Die IP-Adresse des Benutzers kann jedoch nicht durch Filter verschleiert werden, da der Sender zur Datenübertragung über das Internet die IP-Adresse des Empfängers kennen muss. Es ist allerdings möglich, die Daten über anonymisierende Proxy-Server umzuleiten, die dann stellvertretend für den Benutzer die Daten vom Server anfordern und ihn so für den Server unsichtbar machen.
Zum ersten Punkt, der Manipulation der HTTP-Header, ist ein Blick auf die große Anzahl von möglichen Headern hilfreich, die zwischen Server und Browser ausgetauscht werden können. Einige sind notwendig, andere sind optional.
"Cache-Control" (vom Server kommend) kann dem Browser verbieten, die Seite in seinem Zwischenspeicher abzulegen. Ein simples Löschen oder Ignorieren des Wertes wäre als Gegenmaßnahme denkbar.
"Expires" (vom Server) kann dem Browser ebenfalls verbieten, die Seite im Cache zu speichern, bzw. legt einen Zeitpunkt fest, an dem die Daten als veraltet anzusehen sind.
"Pragma: no-cache" (vom Server) kann dem Browser oder auch Proxyservern verbieten, die Seite zwischenzuspeichern.
"R*ferer" (vom Browser übermittelt) teilt dem Server beim Seitenaufruf mit, auf welcher Seite der Browser vorher war. Dies ist eine der wichtigsten Angaben im HTTP-Header, da hierin theoretisch die einfachste Möglichkeit besteht, einen Besucher punktgenau auf seinem Weg über eine Webseite zu verfolgen. Ablesbar ist auch, von welcher fremden Linkliste der Anwender zur eigenen Homepage gelangt ist und einiges mehr. Als Gegenmaßnahme braucht der Headerwert einfach nur gelöscht oder durch beliebigen Text ersetzt werden. Einige Browser wie zum Beispiel Opera bieten sogar die Option, die Übermittlung des R*ferers gezielt abzuschalten.
"Set-cookie" (vom Server) sendet ein Cookie, das im Browser des Benutzer abzulegen ist. Durch Änderung des Wertes kann das Cookie blockiert oder seine Gültigkeitsdauer verändert werden. Inzwischen bieten alle Browser Optionen, um das Verhalten beim Empfang von Cookies differenziert zu kontrollieren.
"User-Agent" (vom Browser) identifiziert den Browser, seine Version und meist auch das verwendete Betriebssystem. Der Wert kann durch jeden beliebigen Text ersetzt werden. Allerdings gibt es Webseiten, die nur bestimmte Browser zulassen oder je nach Browsertyp unterschiedliche Seiten liefern, so dass man unter Umständen keinen Zugang zu einer Seite erhält.
Der zweite Punkt, die Verschleierung der IP-Adresse, ist mit Hilfe von anonymisierende Proxies machbar. Anonymisierende Proxies arbeiten als Zwischenstation zwischen Client und Server und verhindern dadurch, dass der Server die IP-Adresse des Clients erfährt. Außerdem entfernen sie alle nicht notwendigen Header. Viele dieser Proxies haben noch einige Zusatzfunktionen und deaktivieren zum Beispiel Skripte, die den Benutzer verraten könnten. Um noch sicherer oder anonymer zu sein gibt es Proxies, die zum Beispiel für jede Anfrage einen anderen zufällig ausgewählten Proxy-Server auswählt.
2. Cookies
Der differenzierte Umgang mit Cookies erfordert den kombinierten Einsatz von Headerfiltern und Seitenfiltern, da es drei Verfahren zum Setzen und Abfragen von Cookies gibt: Cookies über HTTP- Header, Cookies per Meta-Tag und Cookies per JavaScript.
Verfahren Nummer ein, Cookies per HTTP-Header, wurde im vorangegangenen Kapitel beleuchtet. Es bleiben also Cookies per Meta-Tag und per JavaScript. Beide Verfahren arbeiten über Befehle im Quelltext und fallen somit in den Zuständigkeitsbereich von Seitenfiltern.
Zur Erklärung vorweg: Die Idee, Cookies per Meta-Tag zu setzen, kommt ursprünglich von Netscape und es ist zu vermuten, dass auch nur Netscape-Browser diese Funktion unterstützen. Allerdings interpretieren einige Webserver diesen Meta-Tag und senden das darin enthaltene Cookie als HTTP-Header, der dann von allen Browsern verstanden wird.
Ein typischer Meta-Tag zum Setzen eines Cookies sieht etwa so aus:
<META HTTP-EQUIV="Set-Cookie" CONTENT="cookievalue=Beispiel; expires=Friday, 12-Oct-2001 12:43:21 GMT; path=/">
Die Angabe "expires=..." ist optional. Wenn sie nicht vorhanden ist, wird das Cookie nicht gespeichert und beim Schließen des Browsers gelöscht.
Per Seitenfilter - eingestellt in der passenden Filtersoftware - kann man den Tag entweder ganz löschen oder die Haltbarkeitsangabe entfernen.
In JavaScript ist der Befehl zum Setzen oder Auslesen von Cookies eine Eigenschaft des Objektes "document". Objekteigenschaften verhalten sich in der Regel wie Variablen oder Konstanten. Ein Cookie wird gesetzt und gelesen durch eine Zeile wie diese:
document.cookie = "Testdaten";
variable = document.cookie;
Als Gegenmaßnahme genügt es, per Filter den Befehl zum Setzen des Cookies so zu verändern, dass der Browser ihn nicht mehr versteht.
3. Schnüffelskripte
Dieser Aspekt der Anonymisierung ist von Filtern kaum oder nur sehr schwer zu bewerkstelligen. Die Herausforderung besteht darin, dass jedes Schnüffelskript anders aufgebaut ist. Das Schreiben von wirksamen JavaScript-Filtern kann viele spannende Stunden bescheren. Die Anwender gehen darum oftmals dazu über, JavaScript schlicht komplett abzuschalten.
JAP
Einige Informatiker der Technischen Universität Dresden haben auf Basis des MIX-Verfahrens von David Chaum (wird teilweise für anonyme E-Mails verwendet und gilt als sehr sicher) in Zusammenarbeit mit dem Landeszentrum für Datenschutz Schleswig-Holstein eine Art anonymen Proxy-Server entwickelt. Dieser muss auf dem lokalen PC installiert werden, läuft unter Java und damit auf allen gängigen Betriebssystemen wie beispielsweise Linux, Windows oder Mac. Das Programm verbindet sich über eine verschlüsselte Verbindung mit verschiedenen Servern (derzeit hauptsächlich Uni-Rechner), wobei mehrere Server hintereinander geschalten sind. Sollte sich die Polizei für einen Surfer interessieren und Telefonleitung abhören sowie Log-Dateien vom Provider anfordern, so werden sie nicht viel damit anfangen können. Die durch JAP erreichbare Qualität der Anonymisierung ist sehr starke und geht über eine einfache Proxy-Funktionalität weit hinaus.
Das Programm ist sehr einfach in der Handhabung und es ist sicherer und schneller als die bisherigen Dienste. An JAP wird derzeit noch fleißig gearbeitet, erste Versionen sind allerdings bereits erhältlich (http://anon.inf.tu-dresden.de/).
Was ist ein MIX?
Ein MIX ist ein Proxy-Rechner innerhalb eines MIX-Netzes bzw. einer MIX-Kaskade, der die verschlüsselten Nachrichten der verschiedenen Nutzer eines Kommunikationsnetzes sammelt. Danach kodiert er diese Nachrichten um und sortiert die Reihenfolge für die Ausgabe an den nächstfolgenden MIX neu. Dort findet dann die gleiche Prozedur erneut statt. Der letzte MIX der aktuellen Route bzw. der Kaskade erkennt dann den tatsächlichen Empfänger und sendet diesem die verschlüsselte Nachricht zu. Ein Mix-Netz garantiert eine wirksame Form der Anonymisierung im Internet und arbeitet selbst dann zuverlässig, wenn auch nur ein solcher Mix zuverlässig arbeitet.
Funktionsprinzip von JAP
Die verschiedenen Benutzer des JAP senden ihre Daten (z.B. Seitenanfragen) verschlüsselt an den ersten MIX-Server. Dieser weiß nicht, welche Daten oder Anfragen an ihn gesendet werden, er leitet lediglich die verschlüsselte Anfrage an den nächsten MIX-Server verwürfelt weiter und ersetzt die IP-Adresse des Anwenders durch seine eigene. Der zweite Mix-Server in der Kette dient zur weiteren Verwürfelung der Daten. Der letzte MIX holt die Daten für den Benutzer aus dem Netz und gibt sie dann jeweils an den vorherigen MIX weiter. Erst der Anwender kann die Daten wieder mit Hilfe des Programms entschlüsseln (dies geschieht natürlich automatisch). Die verschiedenen MIX-Server stehen an verschiedenen Standorten, so soll ein Überwachen der kompletten Vorgänge schlechter möglich sein. Solange mindestens ein MIX-Server nicht von Geheimdiensten betrieben wird, bleiben sämtliche Infos anonym, auch wenn die anderen Server alles protokollieren. Derzeit wird im Testbetrieb teilweise der zweite Mix weggelassen und nur mit dem ersten und dritten gearbeitet, es kann allerdings in den Einstellungen auch eine Verbindung über drei Mix-Server ausgewählt werden. Zur bildlichen Anschauung des Funktionsprinzip dienen die beiden unteren Grafiken, sie entstammen der zur Zeit experimentellen Kommandozeilenversion des Programms.


Code-Beispiele
Unbemerkter Mailversand von einer Webseite
<SCRIPT LANGUAGE="JavaScript">
function Loading()
{
document.form1.R*FERRER.value = document.r*ferrer;
document.form1.PLATFORM.value = navigator.appName + " "
+ navigator.appVersion;
document.form1.PAGE.value = document.title;
document.form1.SUBMITTER.click();
}
</script>
<body onLoad="Loading();">
...
</body>
<FORM name="form1" METHOD=post
action="mailto:hans@mustermann.de?SUBJECT=Schon wieder
ein aufgeschlossener Mensch :-)" enctype="text/plain">
<input type="hidden" name="PAGE" value="none">
<input type="hidden" name="R*FERRER" value="none">
<input type="hidden" name="PLATFORM" value="none">
<font size="-1">
<input type="submit" name="SUBMITTER"
value="Belangloser, beliebig kleiner Button">
</font>
</form>
Informationen über den Client Rechner
<SCRIPT LANGUAGE="JavaScript">
function display()
{
window.onerror=null;
colors = window.screen.colorDepth;
document.form.color.value = Math.pow (2, colors);
if (window.screen.fontSmoothingEnabled == true)
document.form.fonts.value = "Yes";
else
document.form.fonts.value = "No";
document.form.navigator.value = navigator.appName;
document.form.version.value = navigator.appVersion;
document.form.colordepth.value = window.screen.colorDepth;
document.form.width.value = window.screen.width;
document.form.height.value = window.screen.height;
document.form.maxwidth.value = window.screen.availWidth;
document.form.maxheight.value = window.screen.availHeight;
document.form.codename.value = navigator.appCodeName;
document.form.platform.value = navigator.platform;
if (navigator.javaEnabled() < 1)
document.form.java.value="No";
if (navigator.javaEnabled() == 1)
document.form.java.value="Yes";
if(navigator.javaEnabled() &&
(navigator.appName != "Microsoft Internet Explorer"))
{
vartool=java.awt.Toolkit.getDefaultToolkit();
addr=java.net.InetAddress.getLocalHost();
host=addr.getHostName();
ip=addr.getHostAddress();
alert("Dein Rechner heißt '" + host +
"'\n\nDeine _lokale_ IP Addresse ist " + ip);
}
}
</script>
Auf MS-Internetexplorer testen
<SCRIPT LANGUAGE="JavaScript">
function getwindowsize()
{
if (navigator.userAgent.indexOf("MSIE") > 0)
{
var sSize = document.body.clientWidth *
document.body.clientHeight;
return sSize;
}
else
{
var sSize = window.outerWidth * window.outerHeight;
return sSize;
}
return;
}
</script>
R*ferer ausgeben
<SCRIPT LANGUAGE="JavaScript">
if (document.r*ferrer)
{
document.write("<B>"+document.r*ferrer+"</B>");
}
else
{
document.write('<center><font size="+1">Du hast einen Bookmark
verwendet (bzw. die URL getippt) oder die Übertragung Deines
R*ferrers verhindert.</font><br><b>Im zweiten Fall: Herzlichen
Glückwunsch !!! :-)</b></center>');
}
</SCRIPT>
Server-Variablen verwerten
<pre>
<?php
foreach ($HTTP_SERVER_VARS as $key => $value)
{
echo "$key => $value\n";
}
?>
Beispiel für eine Ausgabe dieses Skriptes (gekürzt):
HTTP_ACCEPT => text/html, image/png, image/jpeg, image/gif, image/x-xbitmap, */* HTTP_ACCEPT_CHARSET => windows-1252;q=1.0, utf-8;q=1.0, utf-16;q=1.0, iso-8859-1;q=0.6, *;q=0.1 HTTP_ACCEPT_ENCODING => deflate, gzip, x-gzip, identity, *;q=0 HTTP_ACCEPT_LANGUAGE => de,en HTTP_COOKIE => z-board-cookie=%7C1021319692%7C1y HTTP_TE => deflate, gzip, chunked, identity, trailers HTTP_USER_AGENT => Opera/6.01 (Windows 2000; U) [de] REMOTE_ADDR => 193.174.8.65 REMOTE_PORT => 4706 SERVER_ADDR => 193.174.103.20 SERVER_PORT => 80 REQUEST_METHOD => GET QUERY_STRING => REQUEST_URI => /test3.php SCRIPT_NAME => /test3.php